3-JVM垃圾回收算法和垃圾收集器
JVM垃圾回收算法和垃圾收集器
1.什么是垃圾回收
对于内存当中无用的对象进行回收,如何去判断一个对象是不是无用的对象。
引用计数法:
每个对象中都会存储一个引用计数,每增加一个引用就+1,消失一个引用就-1。当引用计数器为0时就会判断该对象是垃圾,进行回收。
但是这样会有一个弊端。就是当有两个对象互相引用时,那么这两个对象的引用计数器都不为0,那么就不会对其进行回收。
可达性分析:
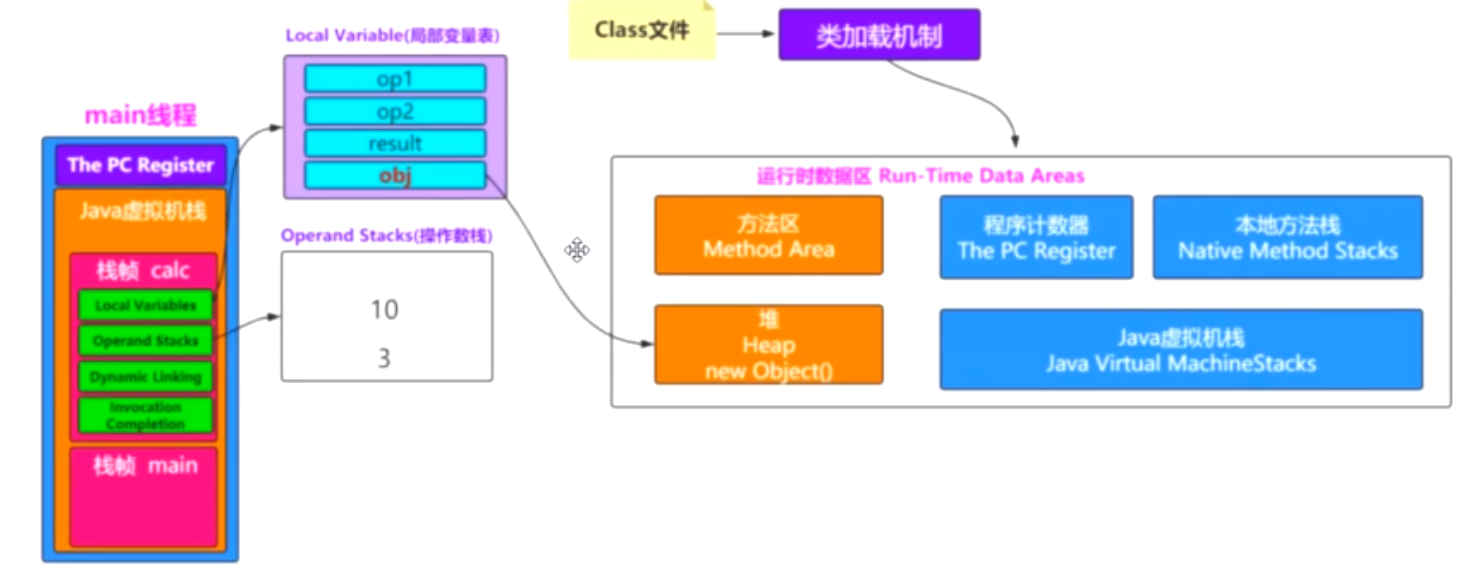
判断某个对象是否可到达。有两种方式判断是否可到达:
直接引用(上帝视角GC Roots):就是虚拟机栈帧中的局部或本地变量表、类加载器、static成员、常量引用、Thread等等中的引用直接到达。
为什么本地或局部变量表里面的变量有它出发就可以用来判断GC Roots的判断标准呢?
因为只用它表示这个栈帧正在被压栈,正在被使用,这个时候再去回收这个对象不是疯了嘛!!!同理static、常量也是一样的道理。
间接引用:通过别人的引用来达到。
并发的可达性分析(并发标记、浮动垃圾):https://mp.weixin.qq.com/s/EgVPlOLArsWb86Kujykn3A
2.垃圾回收的策略
垃圾收集算法
标记-清除
先标记

后清除

弊端一:会有空间碎片问题,空间不连续;这时如果有大一点的对象进来,发现没有连续的空间内存去进行分配,就会再一次的触发垃圾回收机制。
弊端二:在标记和清除的过程中、会扫描整个堆内存;会比较耗时。
有点:简单、明了、好操作。
标记-复制
一开始将这个内存空间一分为二,两边大小相等,一边使用中的,一边是保留区未使用的。划分为这样示例图:

在标记和清除之后,将存活的对象复制到另外一边,在将先前的一边数据全部清除掉。

之后以此反复、两个循环往返。
类似于堆内存中的新生代(Young)区中的Survivor区中的S0、S1,所以堆内存中的新生代(Young)区一定用的就是复制算法。
标记-整理
先标记
后整理。

整理移动之后会得到一片连续的可分配内存空间。解决了空间碎片的问题,但是这种方式在标记和整理移动的过程中也是耗时的。
垃圾收集器:评判一个垃圾收集好坏和调优关注的是【高吞吐量、少停顿时间、少垃圾回收次数】
串行:Serial系列;
并行【吞吐量优先】:Paraller系列;
吞吐量:用户代码执行的时间 / (用户代码执行的时间+垃圾收集时间)99/(99+1)=99%。
适用于后台运算,不需要太多的交互场景。
并发【停顿时间优先】:CMS、G1;
适用于用户交互较多的场景,给用户更好的体验感;如Web应用。
JVM垃圾收集器调优的原则:尽可能在停顿时间较低的情况下,追求高的吞吐量和少的垃圾回收次数。
官方JVM垃圾收集器建议:
- 使用默认垃圾收集器
- 调整JVM堆的大小
- 如果应用程序内存空间比较小(比如100MB),直接选择SerialGC串行收集器。-XX:+UseSerialGC
- 如果应用程序运行在一个单核的CPU,和没有停顿时间要求的情况下;可以让JVM自己去选择或者选择SerialGC串行收集器。-XX:+UseSerialGC
- 如果应用程序更加关注的吞吐量也没有停顿时间要求的情况下,可以让JVM自己去选择或者选择并行的ParallelGC。-XX+UseParallelGC
- 如果应用程序对停顿时间要求比较高(比如小于1秒钟的时间),那么就选择CMS或者G1的收集器。-XX:+UseConcMarkSweepGC 或 -XX:+UseG1GC

G1(Garbage-First):JDK7出现,JDK8推荐使用,JDK9默认垃圾收集器。
G1的整个垃圾收集并清理的过程阶段大体上和CMS收集器是不变的。在最后一个阶段进行删选回收(选择性的回收,进行优先级的回收:优先回收区域(Region)内存活对象较少的)。

重新设计内存空间如图所示:

整个内存划分为一个个大小相等的区域(Region)。逻辑上对这些区域(Region)进行标记,这些标记有Eden区,Survivor区和Old区。这时的物理空间上就不在是连续空间了;之前的空间划分都是连续的空间。假如回收掉某个Old区的数据,这时这个区域也可能会标位Survivor区或者Eden区。
区域(Region)内还有一个记录rememberd Set。以前会全盘扫描堆内存,是比较耗时的。这时会记录一个对象存活的地方,对象的引用指向;这样就不用在全盘扫描了耗时比较低。
官方文档(G1垃圾收集器的前世今生):https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
Young Generation(新生代)- 垃圾收集算法一定是标记-复制算法的实现
Serial:JDK1.3出现的,单线程收集,STW。那时候的CPU还是单核CPU。单线程处理效率比较高,在进行垃圾回收的时候,会暂停业务线程,等待垃圾回收完成之后,在让业务线程再继续执行。会搭配老年代的SerialOld配合使用。
这时会出现Stop The World(STW)

ParNew:并行垃圾收集器多个垃圾线程一起跑,STW ,停顿时间较多,更加关注吞吐量
复制算法、并行多线程垃圾收集器,解决了单线程的局限性,但是还是Stop The World(STW)。

ParallelScavenge
同上
Tenured Generation(老年代)- 这里是标记-清除、或标记-整理的算法实现
CMS:JDK5出现的,并发收集,两个阶段会STW(初始标记、重新标记),更加关注停顿时间。在JDK8中已经不推荐使用,JDK8推荐使用G1收集器。
并发:垃圾收集线程和业务代码线程一起跑。但是并不能做到全程一起执行。
因为垃圾收集线程在执行的时候对垃圾进行标记,这时业务代码线程也在执行,也会产生新的垃圾。至少在垃圾收集线程在进行标记的阶段,业务代码暂定的是不执行的。
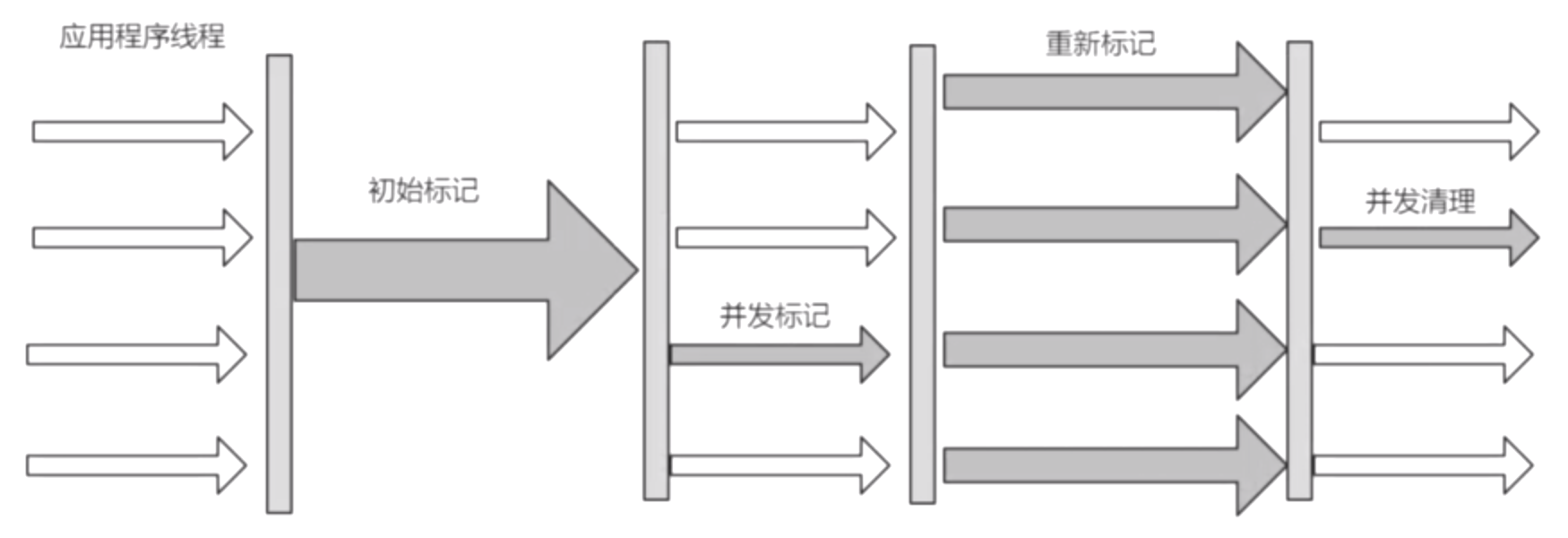
划分为四个阶段:初始标记、并发标记、重新标记、并发清理。
初始标记:第一阶段会Stop The World(STW)。这个阶段执行的时间是非常快的,如果开启多个线程,会消耗线程之前的切换反而会增加时间成本。
并发标记:第二阶段就是可达性分析,对第一阶段的垃圾进行跟踪。在这个阶段垃圾线程和业务线程是一起执行的;为啥可以一起执行呢?因为在第一阶段初始标记完成后大局已定,第二阶段的并发标记只是做增量的更新。如果此时又产生了垃圾那么就是浮动垃圾(把原本消亡的对象错误的标记为存活状态),只能等待下次清理。
重新标记:第三阶段这时会停止业务代码的线程Stop The World(STW),会多线程垃圾收集器并行一起跑,一起执行。
并发清理:第四阶段垃圾收集线程和业务代码线程再次一起执行,一起跑。
特点:并发收集,停顿时间较少。
缺点:会产生浮动垃圾。其次由于采用的是标记-清除这样的算法会产生大量的空间碎片。
Serial Old:串行的

Paraller Old:并行的
如何查看当前JAVA程序应用使用的是什么垃圾收集器:
1 | |