2-Mysql索引原理与使用规则
Mysql索引原理与使用规则
数据库索引到底是什么
是数据库管理系统(DBMS)中一个排序的数据结构,以协助快速查询、更新数据库表中数据。

索引值存储的是建立索引的值,比如说主键id建立索引,在系统中存储的是主键id和该条数据在磁盘中对应的地址;当查询条件根据索引查询时,查到了索引值,然后再根据索引中的地址快速定位到磁盘中的该条数据。
索引的数据结构
数据结构图形工具:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二叉查找树(Binary Search Tree)
左子树的节点小于父节点
右子树的节点大于父节点
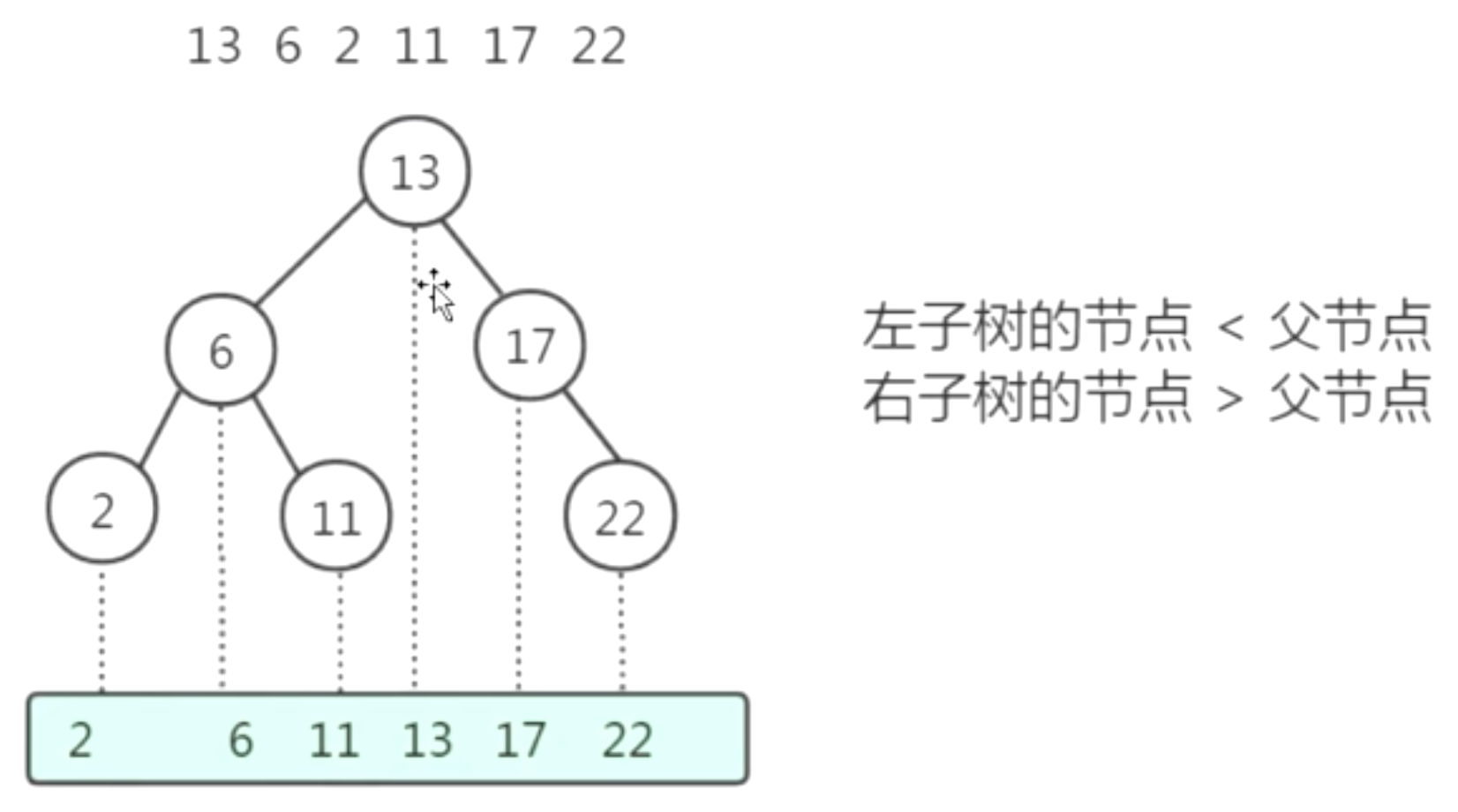
在某些特定情况下,该数据结构会退化成链表形式;当数据按照有序的插入时(正序或倒叙)

平衡二叉树(AVL Tree - Balanced Binary Search Tree)
约束:左右子树的深度差绝对值不能超过1
插入数值后,会对左右子树的节点深度做检查对比,当违反了约束条件后,会根据数值进行左旋(左旋转)或右旋(右旋转)的调整
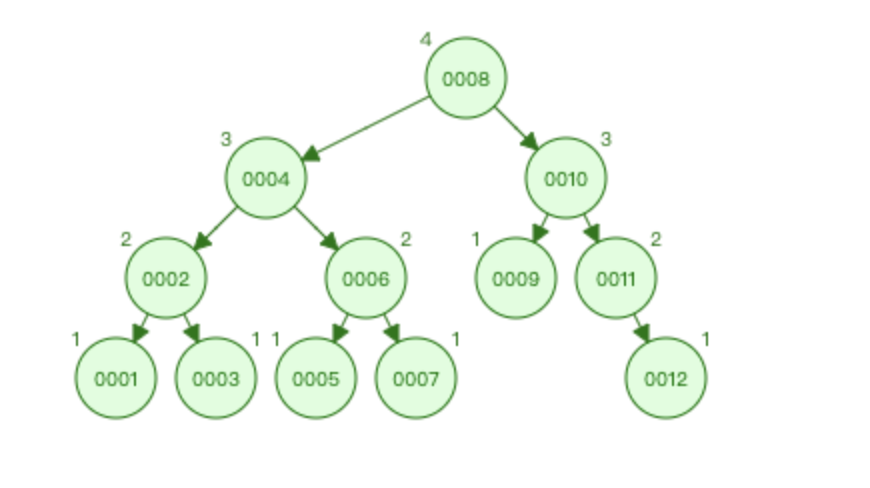
AVL 数据存储
- 键值:建立索引的字段值
- 数据磁盘地址
- 子节点引用
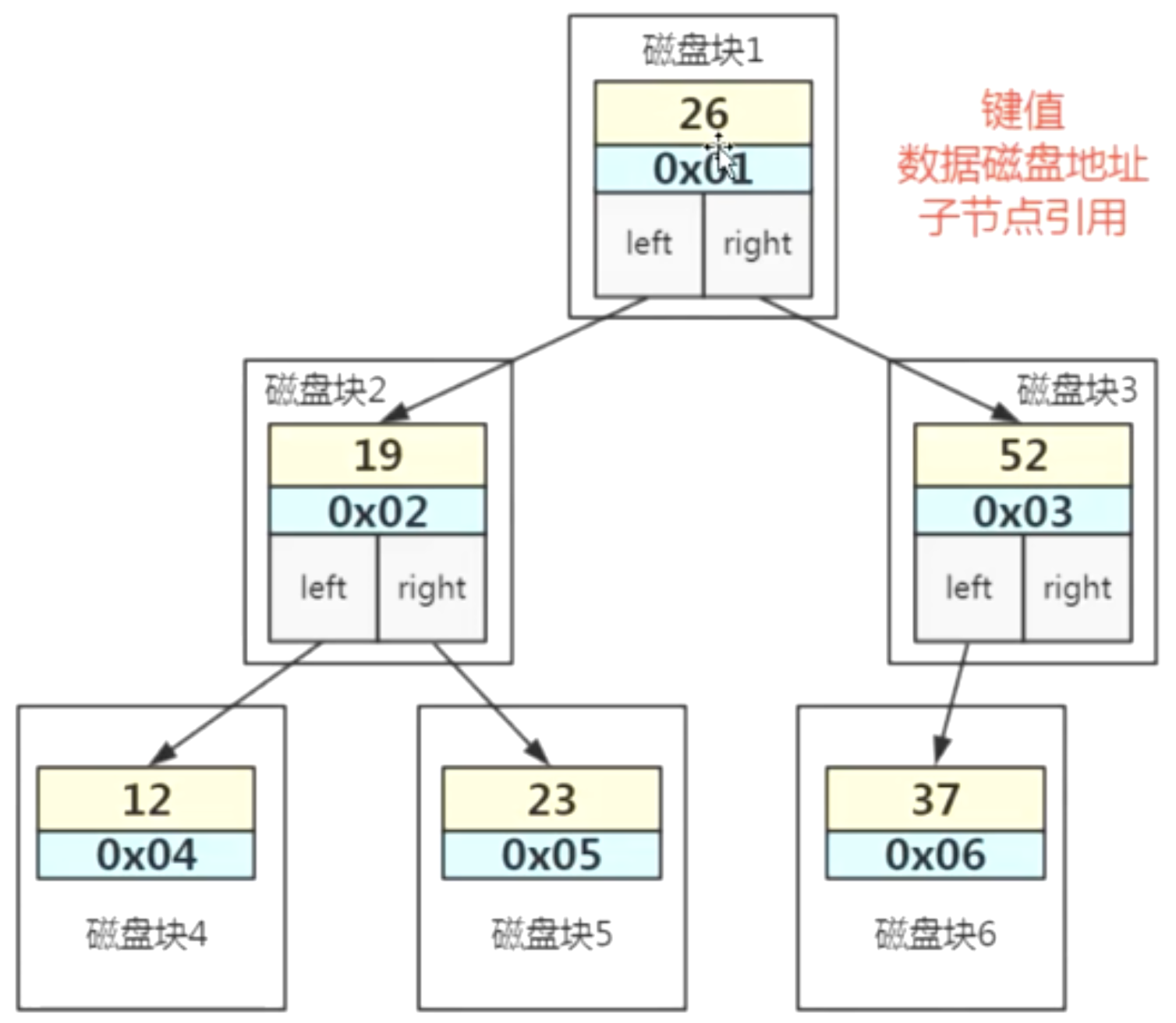
注意:存储引擎从磁盘加载数据到Server层进行比较,这时Mysql加载磁盘数据时最小单位是Page(16 Kb = 16384 bytes);此时单个节点的数据不满16Kb,那么可以将子节点的数据上移,填满一页16Kb的大小,一个节点可以存储多个分叉节点(子节点指针),此时就变成了多路平衡查找树(Balanced Tree B树)
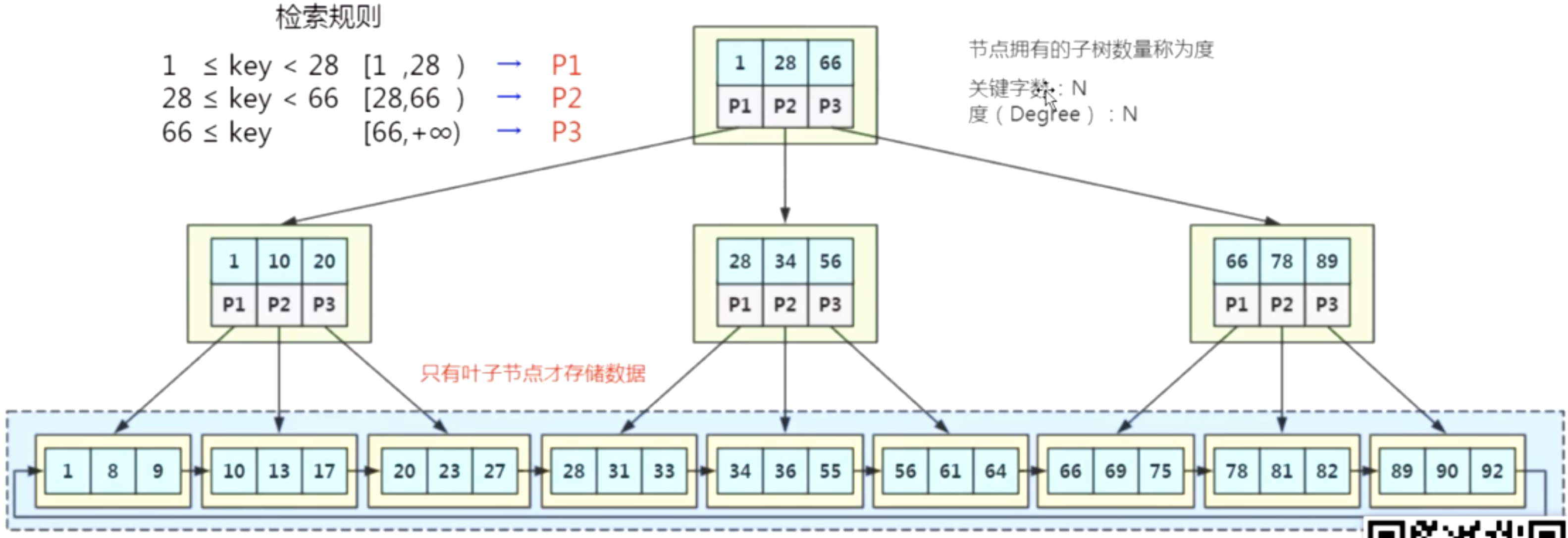
多路平衡查找树(Balanced Tree B树)
特点:更多的键值、更多的节点与子节点指针;键值是N,度(Degree)是N+1,比如节点里存了两个键值,那么度就是3个,有3个分叉,有10个键值的话,有会有11个度,11个分叉。
大大的降低了树的深度
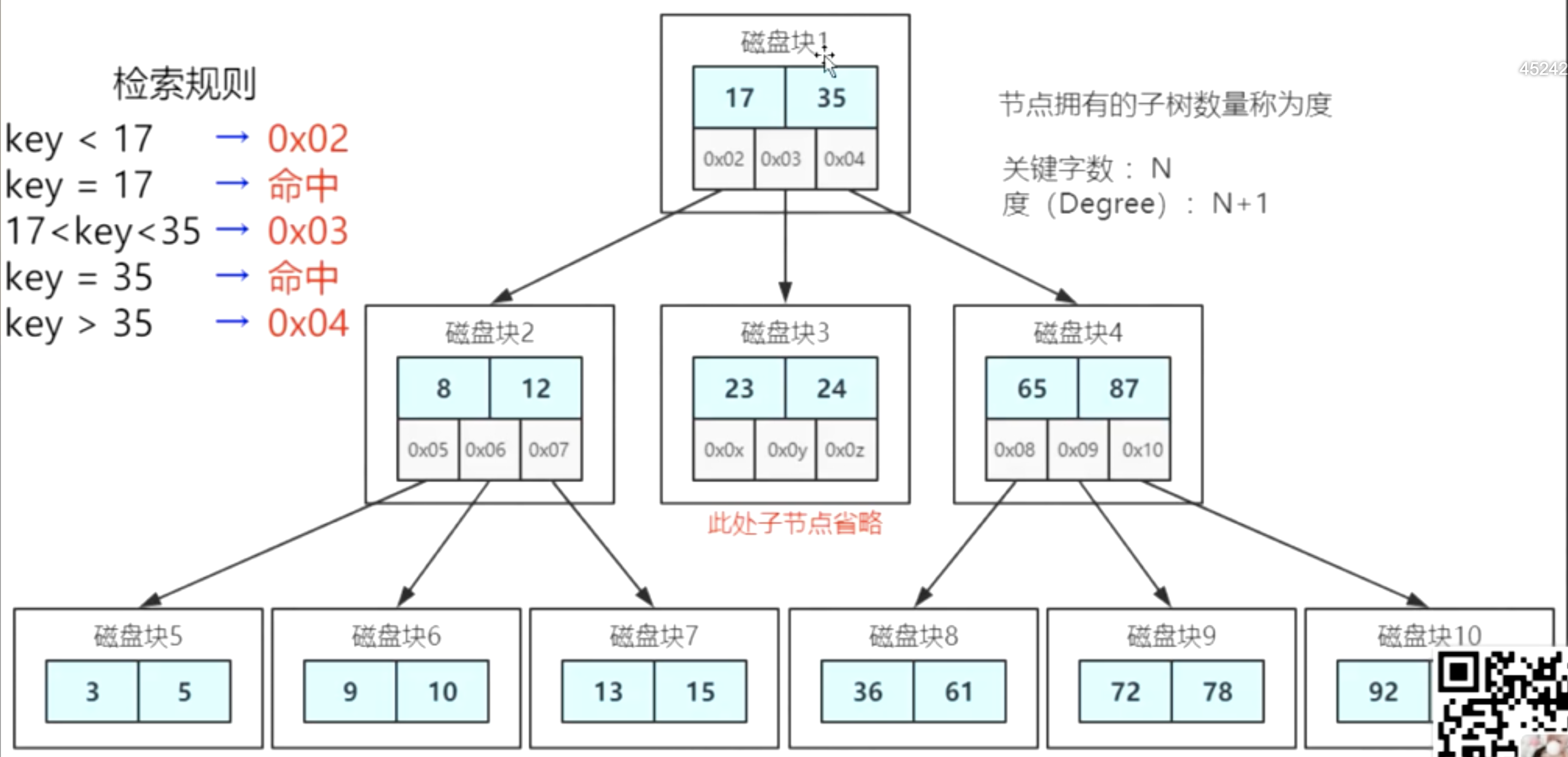
通过分裂、合并保持B树的平衡
当B树不断插入数据时是通过分裂和合并的操作去实现B树的平衡

B+Tree 加强版多路平衡查找树
特点:深度更低、I/O稳定、范围,排序查询的性能大幅度的提升
与B+Tree与B-Tree不同地方在于,它的度(Degree)与键值是相等的。
根节点与子节点不会存储数据在磁盘上的地址,数据一律放到叶子节点上存储,而根节点与子节点存储的是键值与子节点引用指针,进一步减少树的深度。
查找任何数据时,它的I/O次数都是相同的;树整体的深度决定I/O的次数。
叶子节点还有个指针指向下一个相连叶子节点,让叶子节点形成一个有序的链表结构;范围查询时不用再返回根节点遍历查询了,直接通过叶子节点查找就可以了。
优势:
- B-Tree能解决的,B+Tree都能解决
- 扫库、扫表能力更强
- 磁盘读写能力更强
- 排序能力更强
- 效率更加稳定
Hash
在innodb存储引擎中,为热点数据在内存中建立的KV关系;无法创建hash索引的。
在memory存储引擎中是可以简历hash索引的。
索引
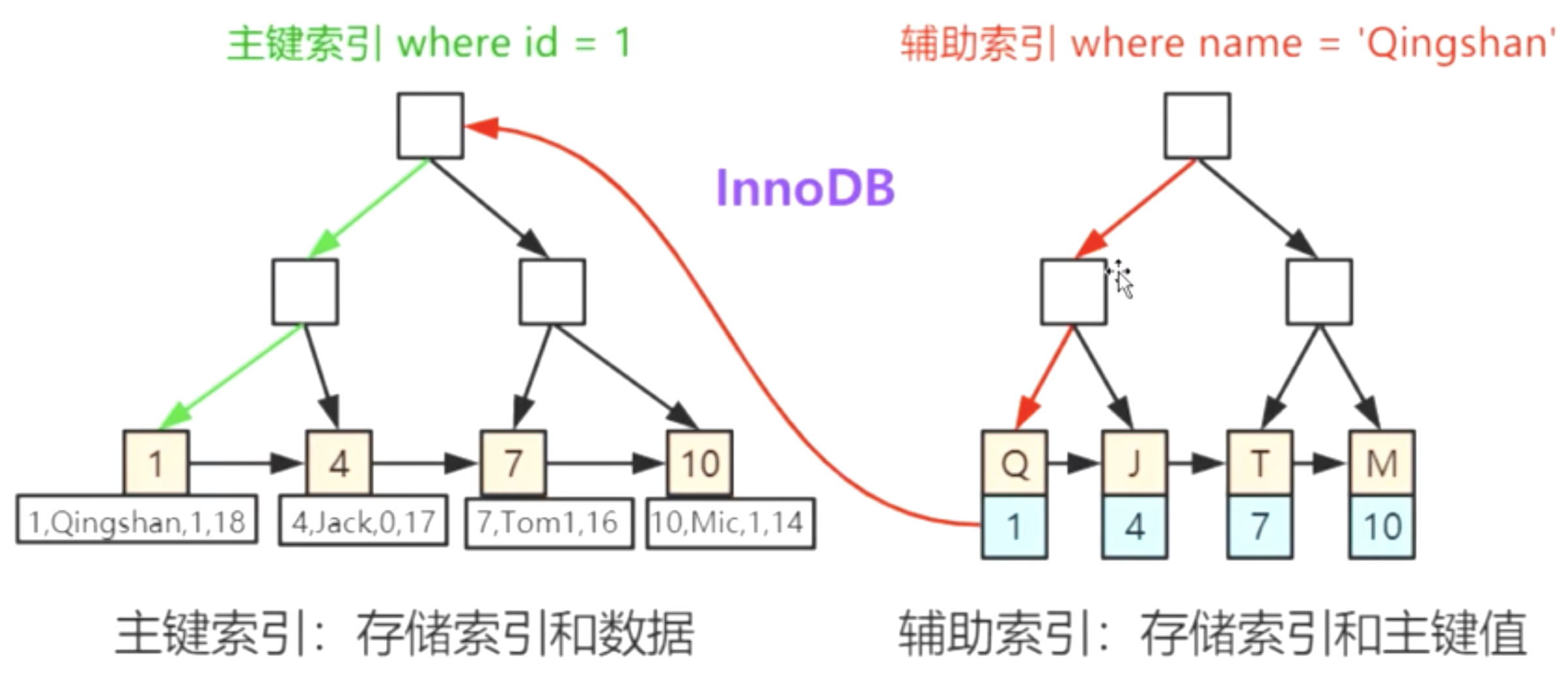
聚集索引(聚簇索引)
索引的键值逻辑顺序与表数据行的物理顺序是一致的;在Innodb存储引擎中,主键索引就是聚集索引(聚簇索引),其他索引叫非聚集索引,又或者叫辅助索引、二级索引
在Innodb存储引擎中,如果一张表没有主键,会找到某个字段是唯一索引并且不能为空的当做聚集索引(聚簇索引);如果一张表中即没有主键也没有唯一并且不能为空的索引,那么存储引擎会自动创建一个隐藏字段_rowid(6 bytes),把它当做该表的聚集索引(聚簇索引)
二级索引(辅助索引、非聚集索引)
创建二级索引时,在Innodb存储引擎中,二级索引的B+树中叶子节点存储的数据是主键值,这样先通过二级索引查找到该数据的主键,然后在通过主键值去主键索引中查找具体数据,该操作也步骤也叫做回表。相比较与聚集索引效率会低下,因为二级索引多查找了一棵索引树。
覆盖索引
查询的数据已经包含在了索引里了;
比如表t,字段有id、name、age,索引有主键索引id,二级索引name。只查找name,这样根据二级索引的B+树查找到了张三的值,就接直接返回张三,不用回表,不用再根据主键值再去查找主键的B+树查数据了,这叫做覆盖索引。
1 | |
索引的使用原则
列的离散度(选择读)公式:count(distinct(count_name)):count(*);重复值越少离散度越高。离散度越小建立的索引使用率越高。
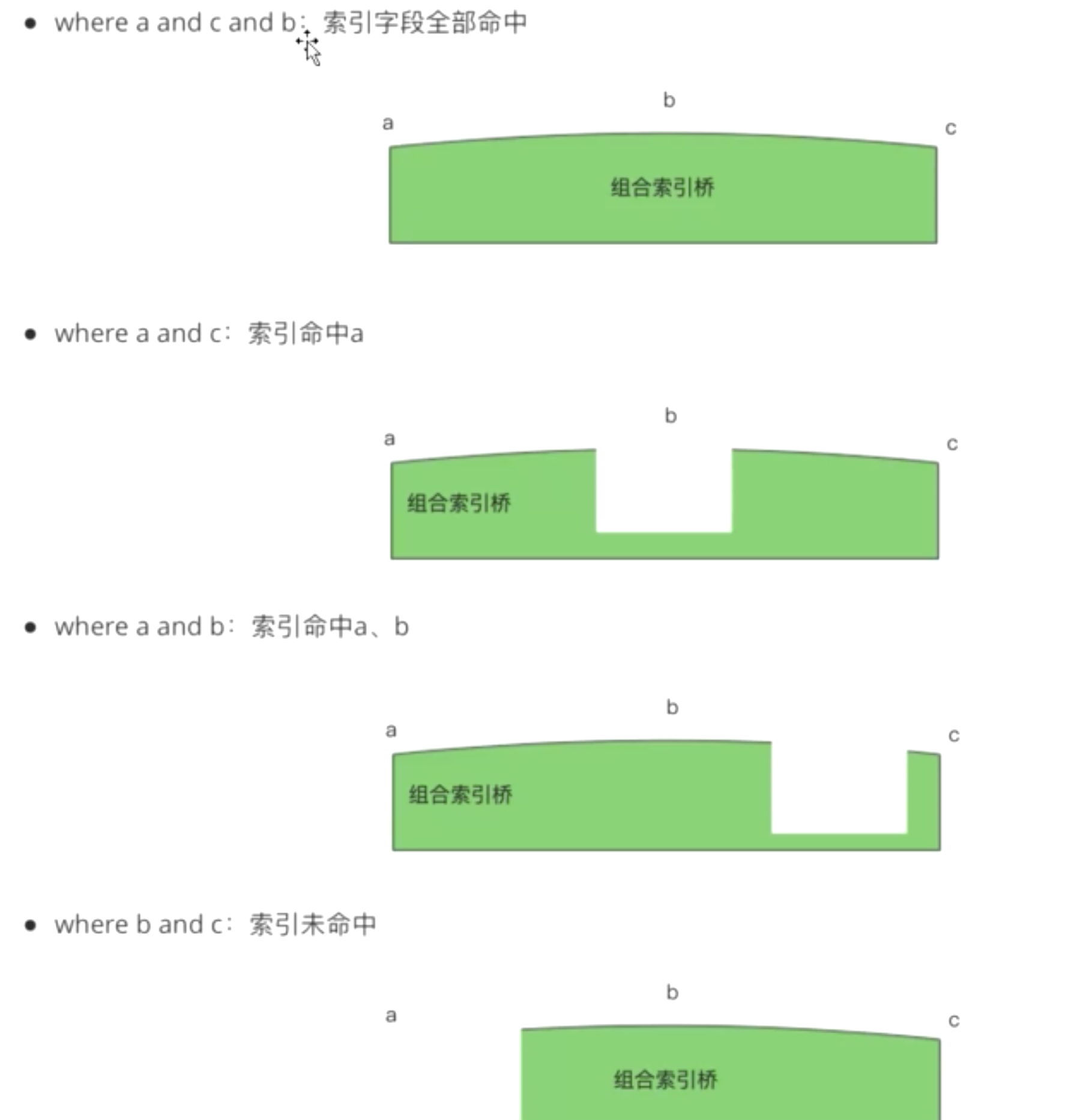
联合索引的最左匹配原则
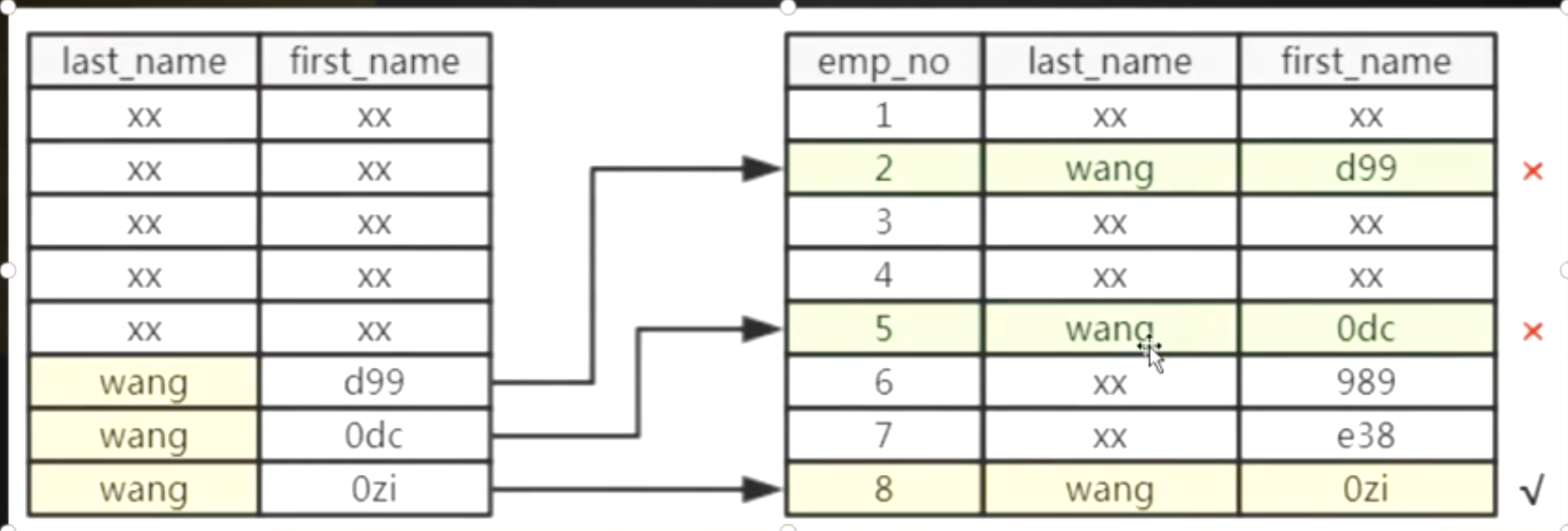
索引下推
1 | |
正常情况下,存储引擎层根据索引查出age='18'的数据,拿到Server层再根据name LIKE '%三'条件再过滤;如果age='18'的数据有很多,那么拿到Server层的数据就很多,过滤也就很慢,代价较大;
所以索引下推就是当存储引擎根据索引过滤出数据过大时,会将原本在Server过滤的条件,不满足于最左原则的索引下推到存储引擎层进行过滤,防止过大的数据到Server层进行过滤。
1 | |
得到结果值:index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,duplicateweedout=on,subquery_materialization_cost_based=on,use_index_extensions=on,condition_fanout_filter=on,derived_merge=on
index_condition_pushdown=on 表示开启索引下推