1-Mysql执行流程与架构
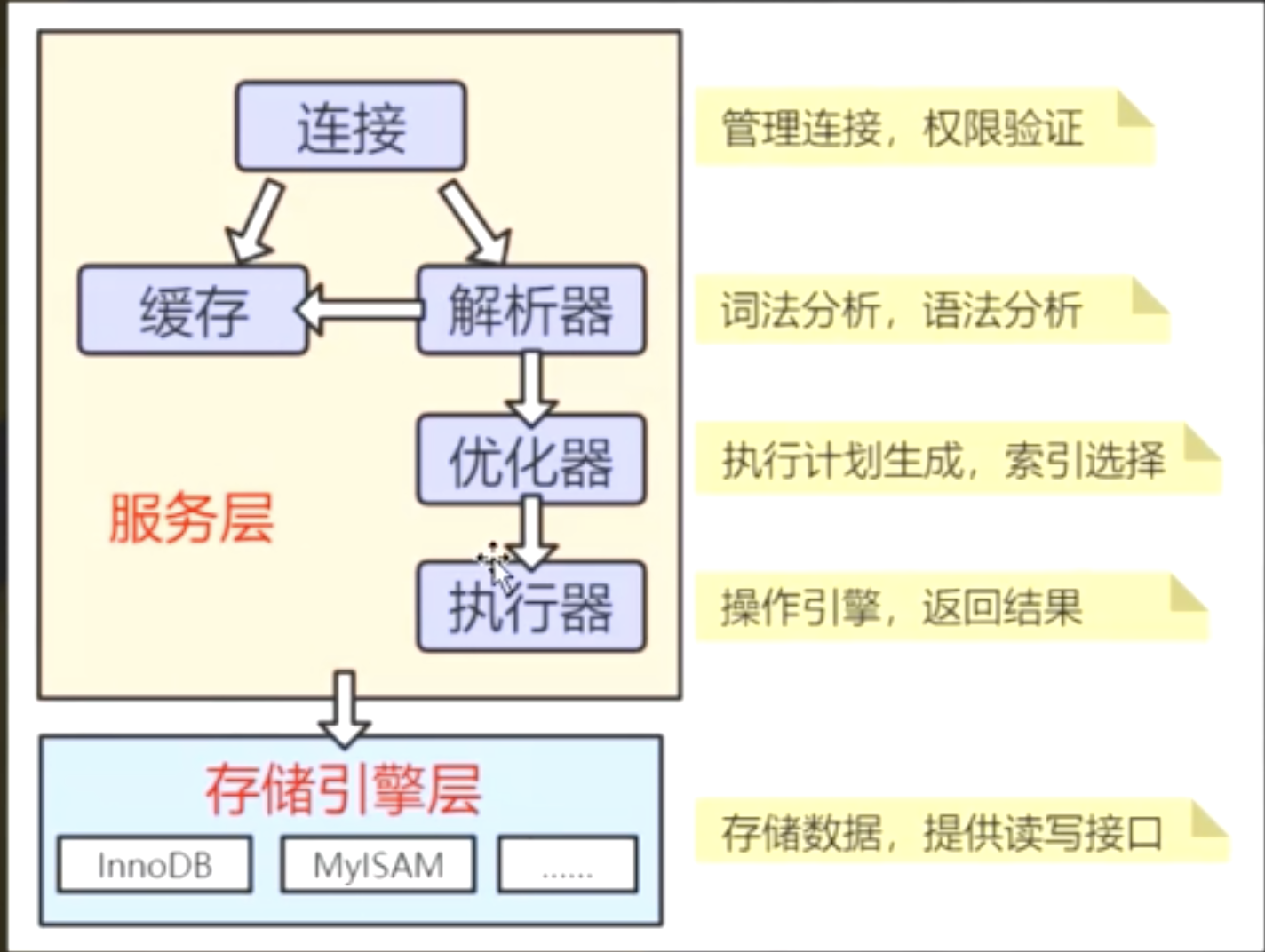
Mysql执行流程与架构
1 | |
1、mysql 缓存
将数据放入到内存中,以KV的形式存储在内存中,减少服务端处理的时间,加快处理速度并返回给客户端。
mysql5.7缓存默认关闭;mysql8.0已移除。show variables like "query_cache%"查看状态已是OFF状态。为什么要移除缓存:
第一点:如果一条sql语句多加了一个空格会认为是不同的sql语句
第二点:缓存是针对表的,而不是针对sql语句;表里有任何数据变化,都会对整张表进行缓存
缓存还是用专业的缓存工具(redis等)
2、预处理器
分析表是否存在,相关权限的校验(用户权限,表增删改查权限)
3、解析器Parser
主要用于分析sql语句:
词法解析-解析成一个一个的单词
语法解析-解析语法规则,比如左边有一个括号”(“,那么右边一定要有个括号”)”
解析树:
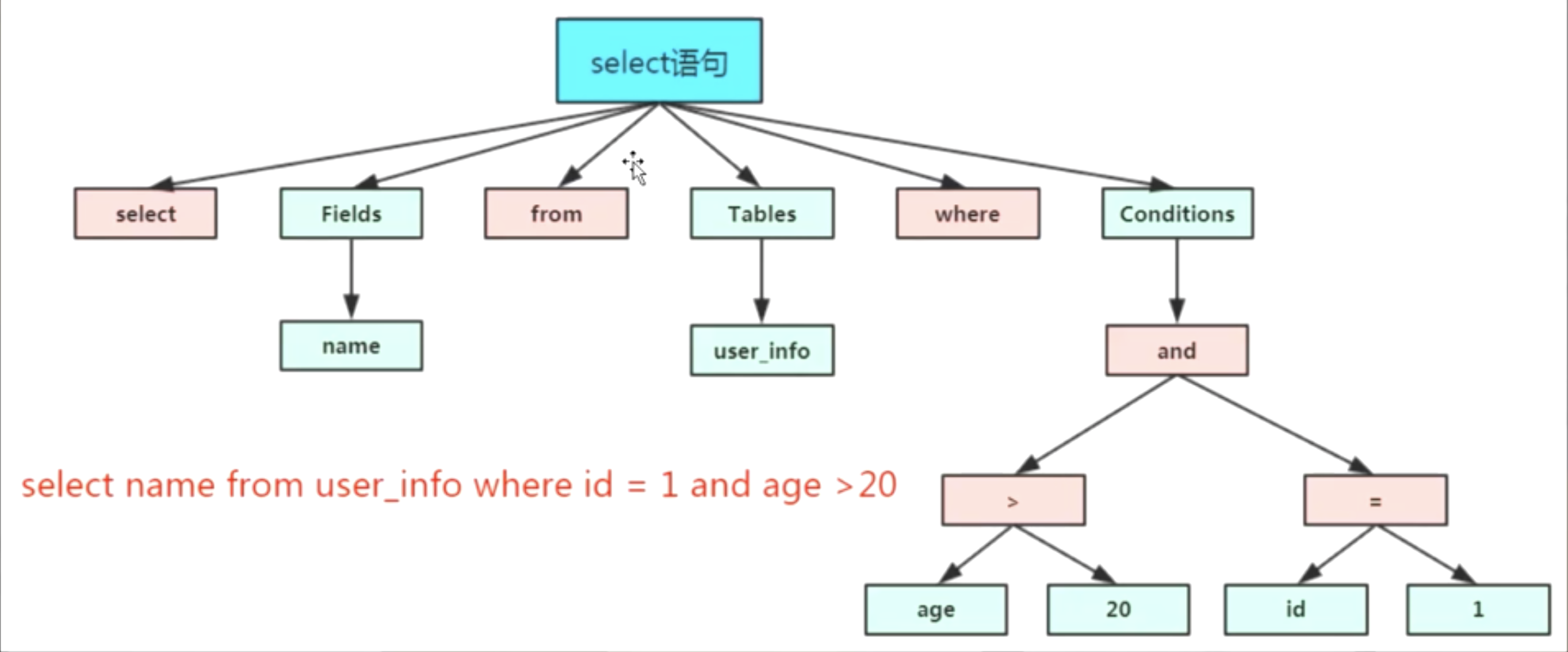
4、优化器Optimizer
成本模型(cost):所有决定都是基于mysql的成本模型去决定的,根据成本模型找出成本最小的最优的方式。
关联查询:决定优先查哪张表
索引:决定是否使用索引或者使用哪个索引
优化器基于解析树再去生成一个数据结构,这个就叫做执行计划。
5、执行计划
优化器得到的结果就是执行计划。
那么如何去查看一条sql语句执行的成本呢?通过这个:
show status like 'Last_query_cost'在调整过sql语句后执行后,前后对比下。格式化成JSON形式查看:
EXPLAIN FORMAT=JSON SELECT t.* FROM t
6、执行器
执行执行计划,并且读写数据。
那么从哪里读写数据呢?
存储引擎-表类型:
查看mysql支持的存储引擎:
show engines插件式的
archive
- 用于历史存储
csv
- 纯文本格式
- 不支持索引
- 用于迁移数据
innodb(5.5版本及之后默认)
每次从磁盘读取的大小是16KB,一页=16KB。
- 支持事务
- 行级锁
- 读写并发操作
- 聚簇索引、非聚簇索引
myisam
- 锁表
- 用于只读场景
memory
- 数据放在内存
- 用于临时表
.
.
.
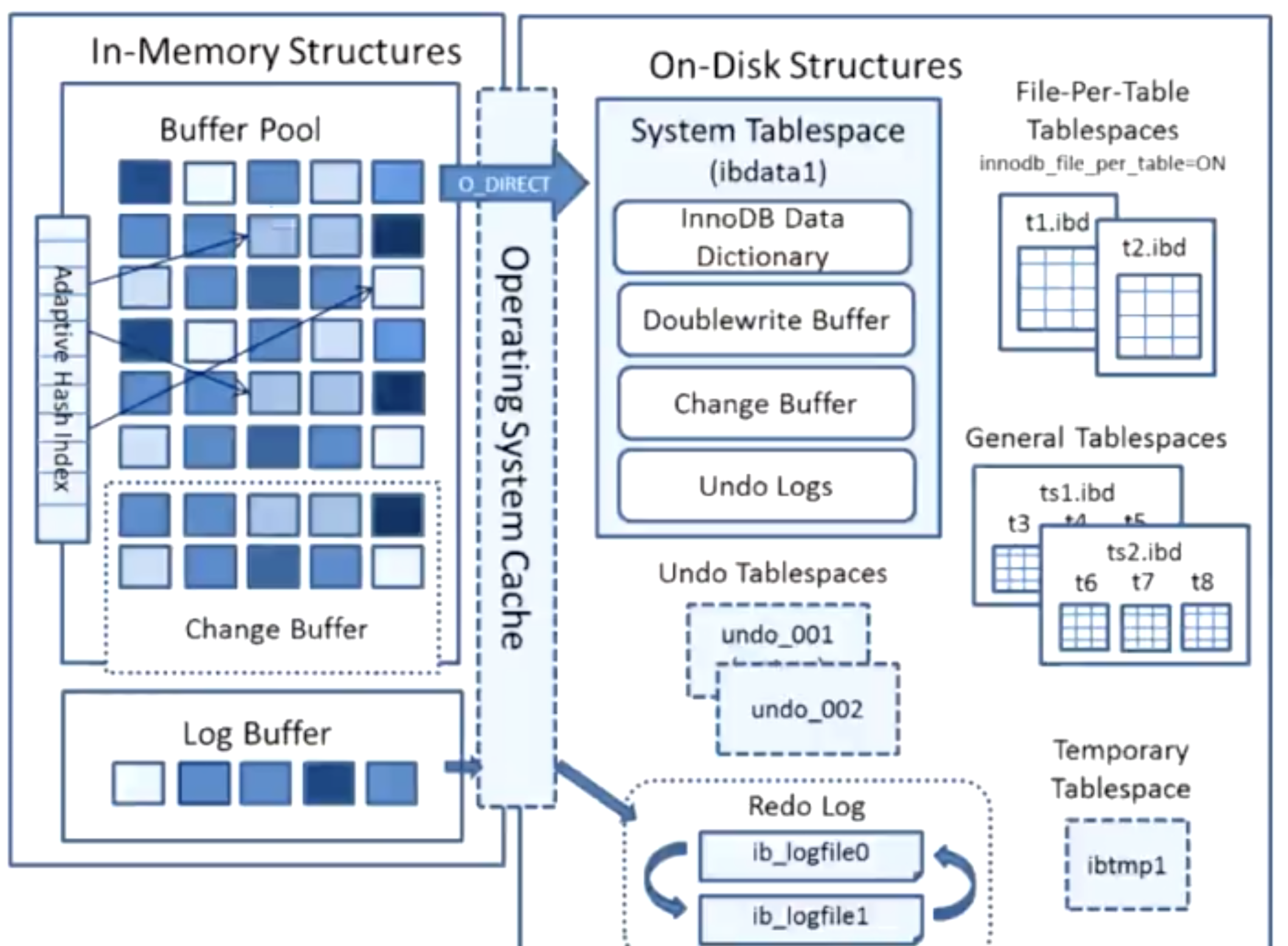
mysql引入了bufferpool内存,用于提升读写的效率。mysql将磁盘数据每次读取的页缓存到了bufferpool,那么每次修改或者写入的时候都是先记录到bufferpool中。
当内存中bufferpool中的数据与磁盘中的数据不一致时,此时页叫做“脏页”,当事务还没有提交的时候、或者两者数据间的时间差就会产生脏页
mysql后台会起一个线程池,当服务端空闲的时候就将bufferpool中的数据写入到磁盘;这个动作叫做“刷脏”
验证bufferpool在mysql中的状态:SHOW STATUS LIKE "%innodb_buffer_pool%"
当刷脏的时候mysql服务宕机了,此时内存中的数据还没有回写到磁盘当中,那么此时的数据会丢失吗?不会,innodb会将内存中数据记录到一个redo log日志文件当中;
“redo log”:
作用就是记录内存中的数据,当出现宕机的情况时,重启之后会从redo log中找到数据并且回写到磁盘当中,
特性:崩溃恢复(crash safe)。
为什么要引入redo log,而不直接写入到磁盘中呢?因为写入到磁盘需要先读取数据,在磁盘当中寻找地址的过程:随机IO,而记录到log文件中是:顺序IO;顺序IO一定比随机IO速度要快的(顺序IO > 随机IO)。
文件大小是固定的,当日志文件记录达到最大文件大小时,会将数据刷到磁盘中,同时释放出一部分文件大小用来记录新的日志;以此类推,是不断循环覆盖的。
“undo log”:
记录的是事务发生前的数据的状态
保证原子性:要么全部成功,要么全部失败
只有增删改的记录,查询是没有的
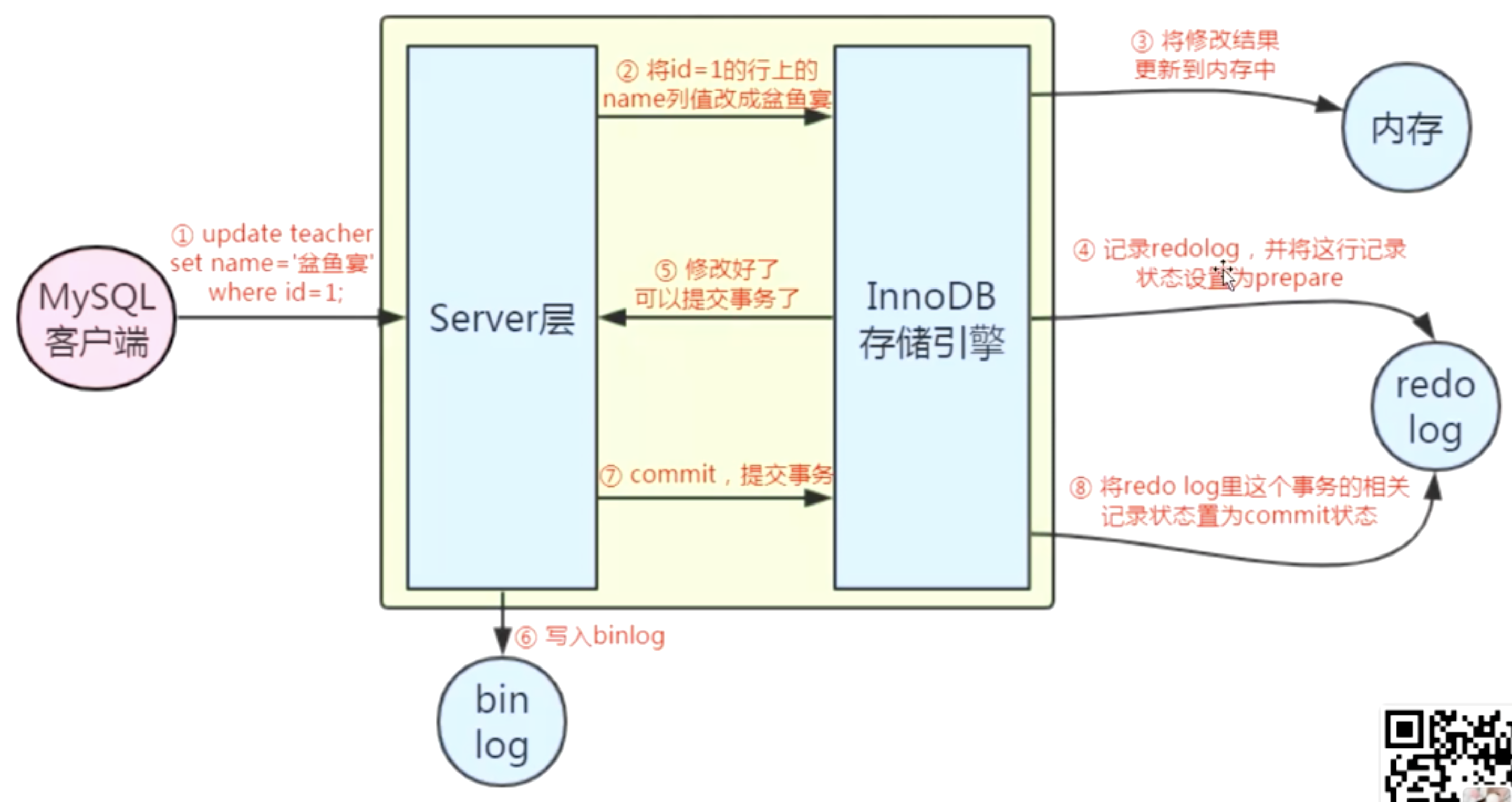
更新语句执行流程: